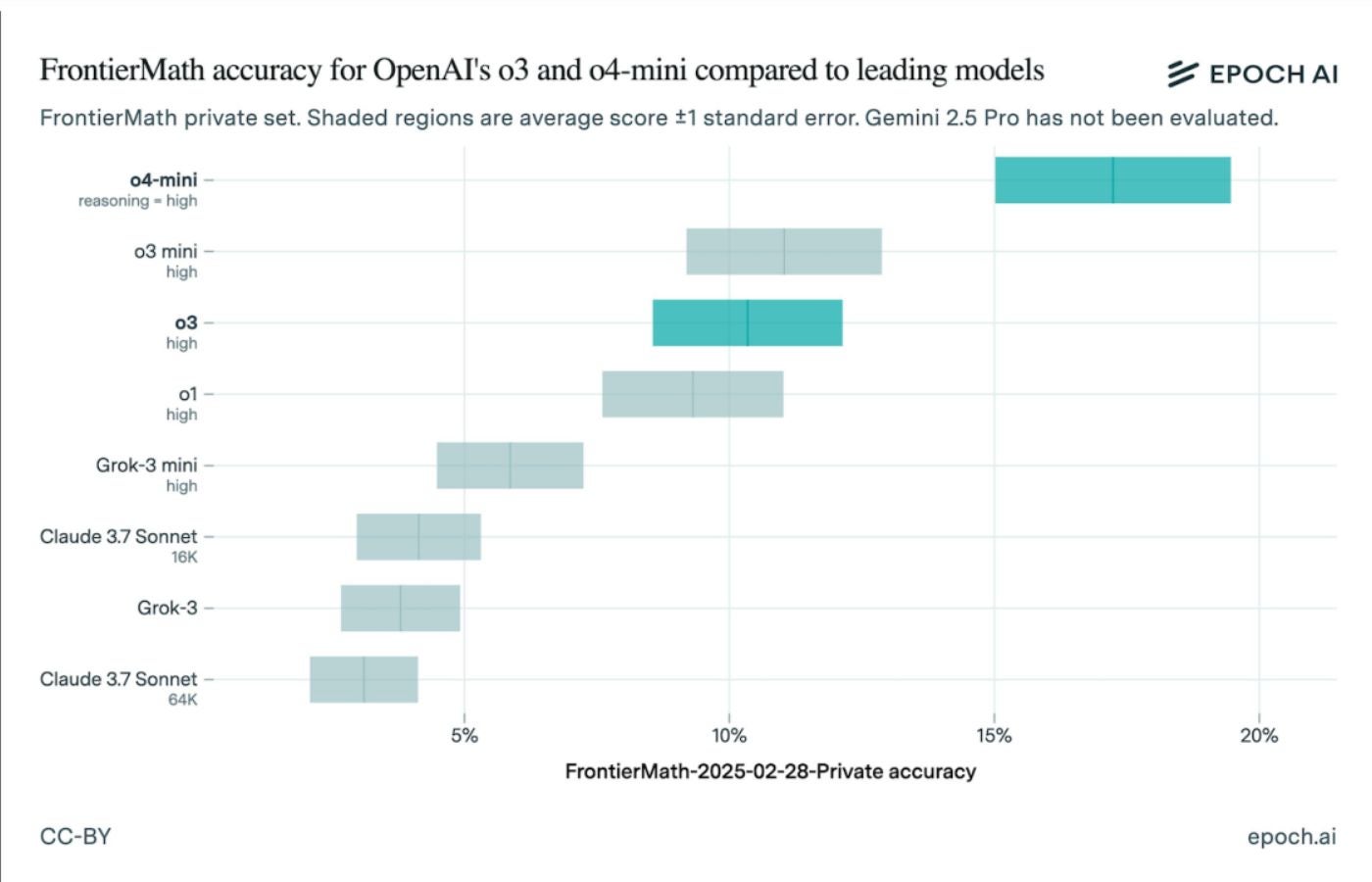
AI Benchmark Discrepancy Reveals Gaps in Performance Claims
FrontierMath accuracy for OpenAI’s o3 and o4-mini compared to leading models. Image:…
Which Two AI Models Are ‘Unfaithful’ at Least 25% of the Time About Their ‘Reasoning’?
Anthropic’s Claude 3.7 Sonnet. Image: Anthropic/YouTube Anthropic released a new study on…

Anthropic Releases Claude 3.7 Sonnet AI Model With Reasoning Capabilities, Introduces Claude Code
Anthropic released an upgraded version of its Claude 3.5 Sonnet artificial intelligence…